
Recent Weights Ensembel Techniques in Deep Learning
Published:
Disclaimer: To write this blog I read several blogs from Medium authors Max Pechyonkin and Vitaly Bushaev. Thanks to them and the relevant arxiv papers. Also I referto this beautiful blog.
Summary
Ensemble is common way for kagglers to get the best performance by commbining the performances of different models. In practice, serveral kagglers share their own best-performance models to ensemble them to a final best one. Xgboost and other boost methods are thus becoming the secret weapons for the final round kagglers. However, it is difficult to train so many models in research to boost the performance by serveral points or so for the GPU computing is quite expensive. We still want to take the advantages of ensemble. So the first weights ensemble comes. Before that, let’s look at some relevant techniques in training.
Before start
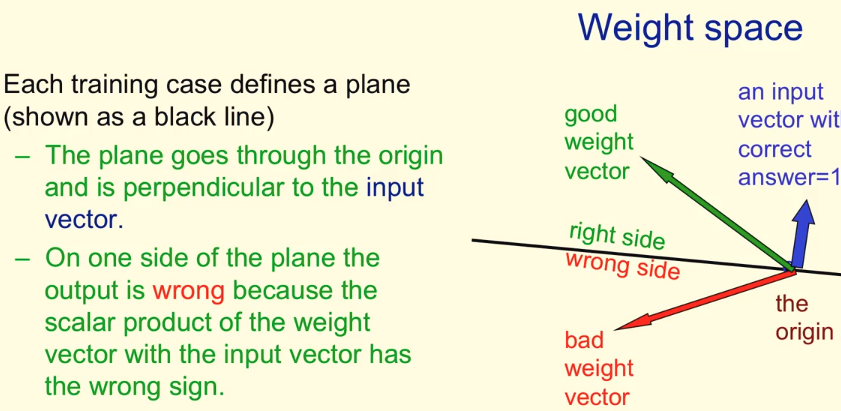
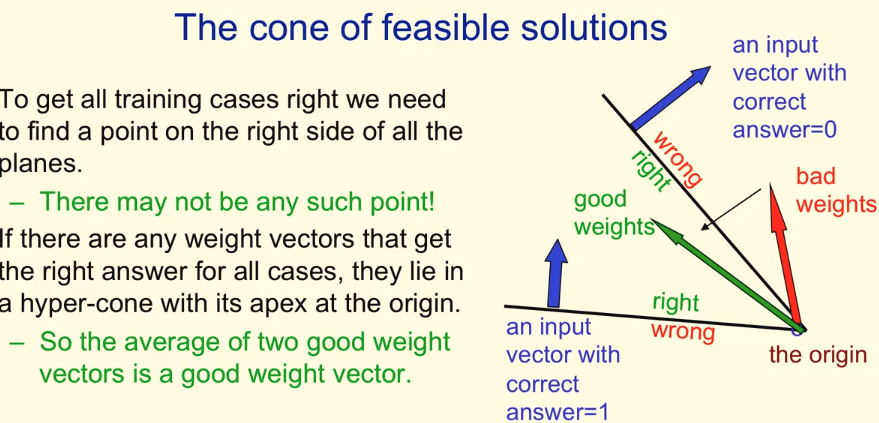
Geometric Views of weights
At any point of training. The network with the weights in it, or the solution we have so far can be viewd as a vector while the inputs can be viewd as a plane. Our goal is to find such “good” vectors that can seperate the input planes, or find vectors which multiplies with the input vectors can lead to positive sign of the plane. The solution space is concave, thus two such good solutions can combine to make a new good solution. This is a base knowledge that we can emsemble our weights to get a better one.
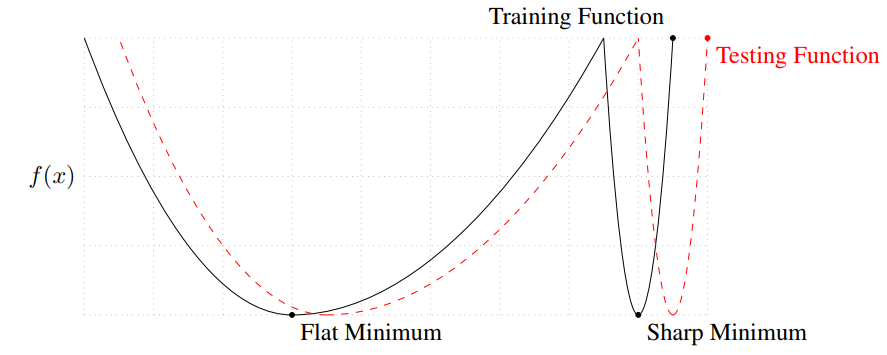
Wide-Sharpe-Minimum
As in the paper ON LARGE-BATCH TRAINING FOR DEEP LEARNING:GENERALIZATION GAP AND SHARP MINIMA (I should have read it earlier!). The ability of generation from training set to test set is viewed as the problem whether the minimum is sharpe or wide. Just as the figure below, the good(well generalized) solution should be the wider ones.
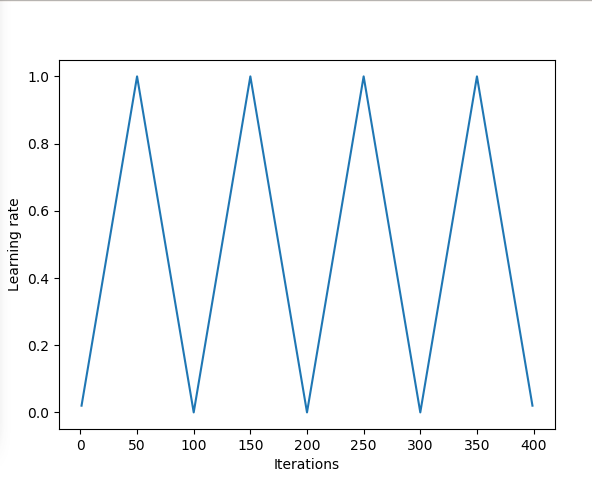
Learning rate schedule
You can refer to this blog for more details about this part. We usually use constant learning rates during training. But the problem is that such constant lr can lead to traing stuck at the saddle point. In Leslie N. Smith’s “triangular” learning rate paper, a triangle shape learning rate is proposed to alleviate the problem. Inspired by this, cosine lr up and down also comes out and proves to be more effective.
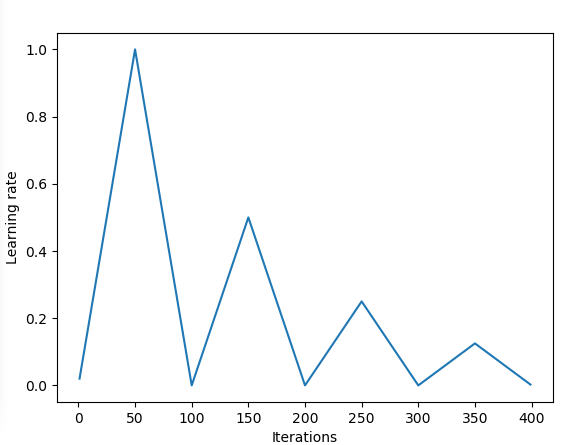
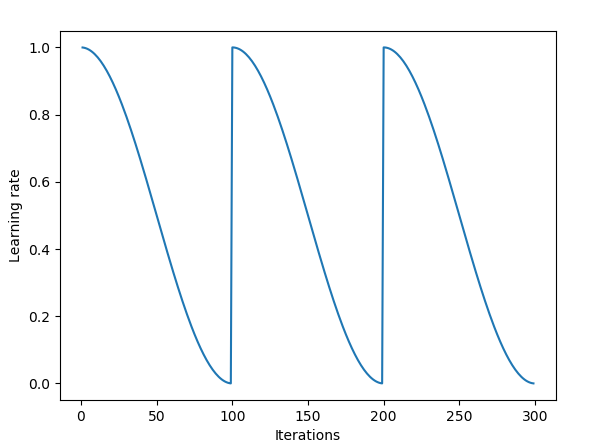
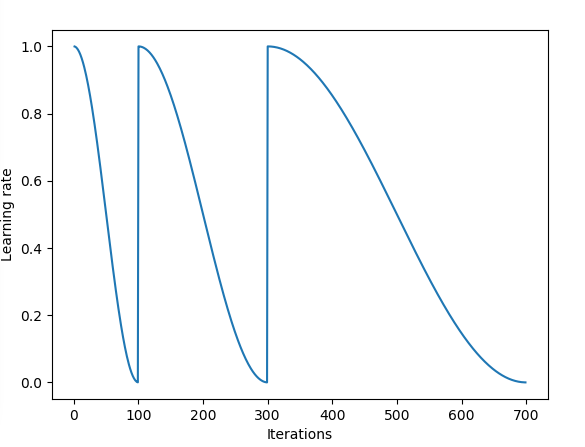
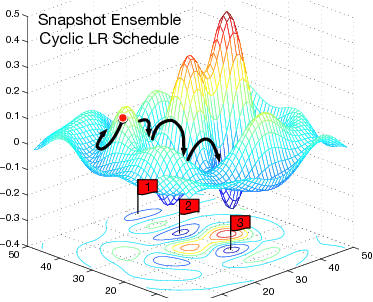
Snapshot Ensembling
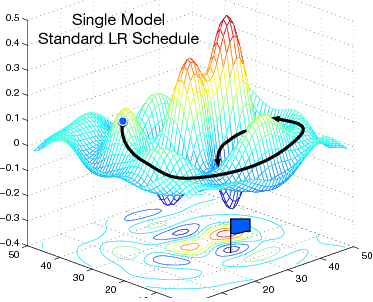
Ensemble weights of different local minimums
Unlike other model ensemble methods. The author comes up with the creative idea of increasing the learning rate to escape the current local minimum instead of training from start over to get another minum. Thus the training cost is cut down sharply. I followed the Keras code implementation to get a 71.04, 71.78 and 72.24 accuracy on the CIFAR100 dataset using single best model, non-weighted ensemble model, weighted ensemble model respectively.
Fast Geometric Ensembling
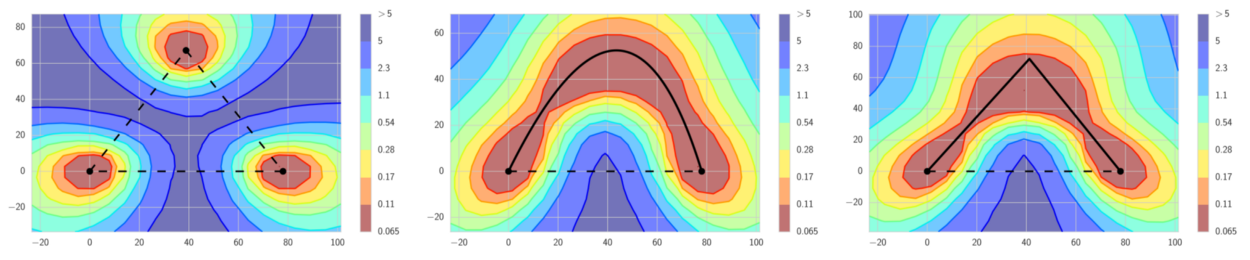
Ensemble minimas on the the path
The authors found that there exists path between the local minimas, on this path the loss stays low. Therefore it can take smaller steps and shorter cycles to find different enough minimas to ensemble with, and produce better results than the Snapshot Ensembling.
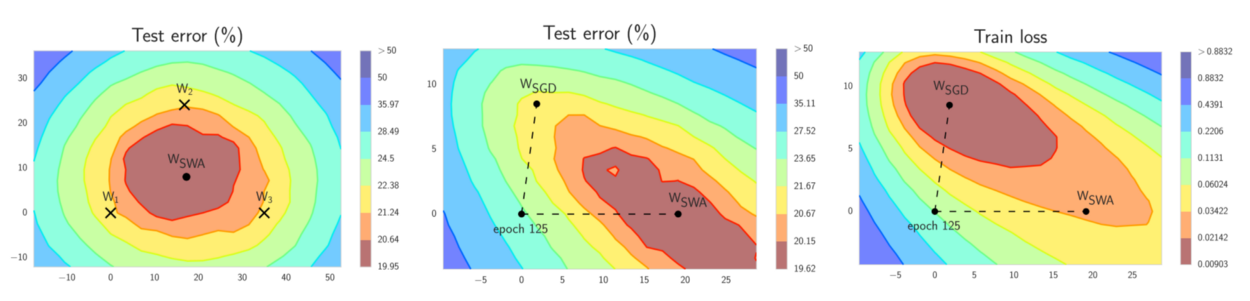
Stochastic Weight Averaging (SWA)
Only two set of weights to ensemble
The Author observes that after every cycle, the solution stops at the boarder of the “real global minima”, so intuitively just average these solution weights. In practice, the paper gives a formula to let two set of weights to update the averaging. And at last one final weight is used to inference.
\[ \frac{w_{SWA} + n_{models} + w}{n_{models}+1} \to w_{SWA}. \]
This is the formula to update the average after get a new minima
Update on Feb,23: the same group put a new paper “SWAG” “A Simple Baseline for Bayesian Uncertainty in Deep Learning”, pdf link
to be continued….
Leave a Comment